Robotics Web3 DevOps Stack
The DevOps movement has revolutionized the IT world and reshaped our understanding of effective, continuous system improvement. The robotics field is just starting to explore this approach. In this article, we envision the potential future of DevOps for robotics using Web3 technologies. We also highlight a few projects that could lay the foundation for this future.

Origins of Development & Operations
Robots, as moving and sensing the external world devices, are a specific case of computers. As engineers often say, an airplane is a flying computer, emphasizing the importance of the onboard computing device for maintaining the viability of this cyber-physical system. Therefore, we can look at how the world of information systems has developed in the 21st century and identify certain trends that will be inherent in robotics in the very near future.
Software and the practices used for its development have significantly changed approaches to work in both engineering and any other activity. First and foremost, the changes affected the so-called waterfall approach, when any project was seen as a series of lengthy alternating stages: Requirements - Development - Verification - Validation - Operation. Over time, it turned out that the division into stages is convenient for managers, but does not quite correspond to how it happens in life and complicates the rapid adaptation of products in the conditions of a constantly changing external world. Agile methodologies, implying synchronous work on the project with small planning intervals, came to replace the waterfall model of activity (and management). Instead of large stages with milestones, there were small sprints with increments - small but frequent changes in the developed systems with a quick release. Such a pace of work is unattainable if the release is accompanied by complex administrative procedures with manual checks. Thus, the Development & Operations movement emerged to implement practices of transferring value from developers to consumers without losses and a new profession of a DevOps engineer, automating the process of quickly putting the system into operation.
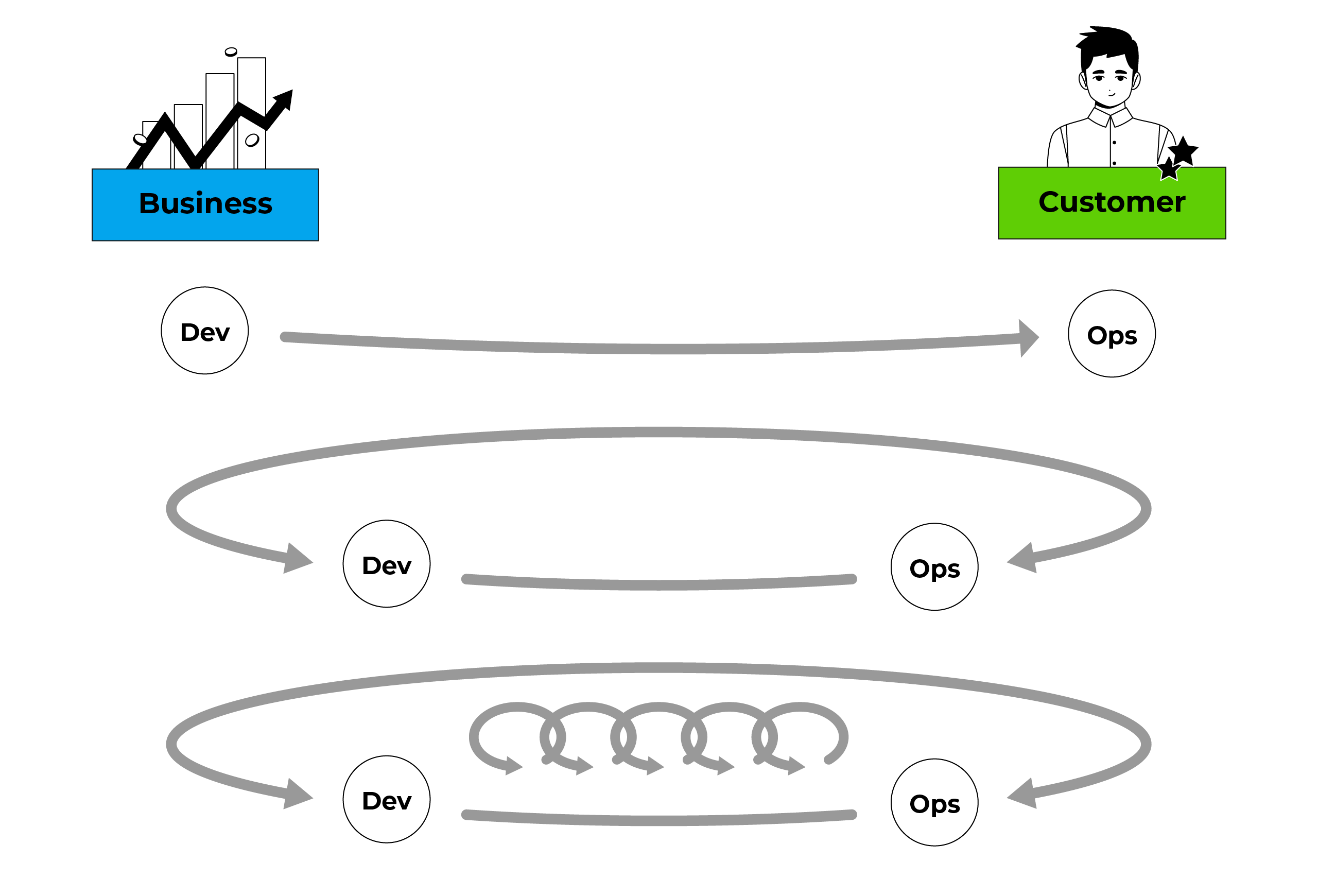
These practices include automated testing, continuous integration, delivery, deployment, and software monitoring. Automated testing checks for bugs, while continuous integration integrates code changes frequently to detect issues early. Delivery and deployment involve getting the software to users and installation in their environment.
Initially, these practices gained momentum in the area of large web services, which serve millions of users around the world. In such a context, these practices are crucial for maintaining the high performance and reliability expected from such services. However, as time has progressed, and automation tools have become more accessible (partly due to open source contributions), DevOps has begun to be used in more traditional types of engineering activities. Therefore, these practices have transcended their initial domain and are now employed across various sectors to improve efficiency, reliability, and quality of software products.
Key Features of Robots in the Context of DevOps
Robots, unlike stationary servers and data centers, move in space and sense the external environment. More and more of such devices are emerging. We see their computational power growing over time - many technical solutions would simply be impossible without a powerful onboard processor.
With the increase in edge computing, which refers to computing on the mobile devices themselves, the use of DevOps is becoming more popular. This approach allows for rapid delivery of newly developed features to consumers. Robots can be continuously connected to the network and promptly update their software using Docker and other tools proven in practice.
However, additional capabilities create additional risks - by empowering computers with the ability to interact intensively with the external environment and the internet simultaneously, we create prerequisites for potential harm that these devices can inflict if they fall under the control of malefactors. Smart devices, gradually filling our homes, can suddenly go mad! The issue of security here is of paramount importance in a constantly changing world, because all these devices are in close proximity to our bodies. Mistakes can cost too much.
What makes robotics special and sets it apart from other computers? These special features include:
- A variety of hardware platforms (compared to a relatively small number of central processor architecture types)
- Working in unpredictable environments, which implies the presence of emergency situations - for example, unavailability over communication channels
- Limited resources of on-board computing devices - weak processor, relatively small amount of memory and low network bandwidth
- Increased safety requirements
- A large number of devices that require updates and new features
Considering these restrictions, we will try to formulate a conceptual basis for DevOps for robots based on Web3 technologies, at least, for writing code, building, and deploying. We will try to present the most interesting Web3 projects capable of ensuring the functioning of a decentralized DevOps conveyor and show how Robonomics can become an integral part of it in the final phase of the life cycle - when implementing programs in the external world.
Web3 and Blockchain
When we talk about Web3, we primarily mean Blockchain technology. These are of course closely related concepts, but not exactly identical. Often under this concept a whole set of technologies is implied - elliptic curve cryptography, P2P networks, consensus algorithm. The first two points are not something unique and are widely used in the IT industry, while the latter really endows the blockchain with a special feature, making this solution such a powerful tool. But do we need consensus for all life situations (and parts of the DevOps conveyor)? Let’s try to figure it out.
Consensus has different meanings in different contexts, but its essence is always unchanged - systems, actors, or autonomous agents that make up a decentralized network come to an agreement on which protocol they use in work and the state of common data. If the parties do not come to an agreement, this leads to the so-called Fork. Historically, a fork implied a split of the blockchain, which led to the division of the network nodes into two parts - some nodes remained “loyal” to the old version of the protocol, while the rest switched to the new version. This event always had a negative context - the community was decreasing instead of consolidating, which made the project somehow weaker. At the same time, as in biological evolution, as well as in its techno-version observed by us now in the form of economy, branching occurs constantly and, moreover, it leads to the emergence of new forms of life. Look at the tree of life. Each branch on it is a Fork that occurred in ancient times - a mutation gave birth to a new species that became incompatible with its tribesmen. Without this mechanism, life in its modern understanding would be impossible. It is the ability of organisms to mutate that allows them to adapt to changing environmental conditions.
Thus, we come to the conclusion that consensus is both good, because it allows for the coordination of many actors and scalability, but at the same time it is bad, because it hinders the emergence of the new, as those who deviate from the consensus are always considered outcasts and the system kind of “pushes” them out.
Unlike biological evolution, we humans carry out techno-evolution, and it depends on us how this evolution takes place. The source of mutations in technology is engineers, applying the scientific method and creative thinking to produce new, more promising and viable versions of technology. We benefit from more frequent mutations, we benefit from decentralization in the sphere of generating new effective solutions both in relation to technology and organizations. On the contrary - a situation where one point of view “wins” and full and unconditional consensus is achieved, is fraught with the risk of collapse under certain circumstances. That is why nature did not go the way of creating super-organisms the size of a planet, but went the way of decentralization - when all living beings are scattered across ecological niches and ecosystems, which makes life as a whole stable and even stabilizes the planet Earth according to the Daisyworld model (in short, thanks to the biosphere and its diversity, the planet becomes more stable).
So, why this digression? Primarily, I want to emphasize that not all data requires mandatory consensus, making blockchain inappropriate for every scenario. Consensus becomes necessary when uncoordinated actions could result in irreversible consequences. For instance, it’s crucial at road intersections. If there’s no agreement on traffic rules regarding when to go and when to stop, you can imagine the potential chaos!
Returning to the main topic of the article, it can be assumed that consensus is appropriate where the risks are high and, conversely, in cases where the risks are small, it is more appropriate to choose a completely decentralized system without consensus. Code development itself is a relatively safe activity, as long as it remains in the state of source or even executable files on the build server. However, when it comes to deploying these files in the physical infrastructure of the real world, it is very important to be consistent. That is why for the first two points of our DevOps stack (development and build) we chose like-minded projects without consensus.
First Phase - Development - Radicle
So, in code development, complete freedom and decentralization are needed to stimulate the generation of the best solutions directly from the authors. Fortunately for us, in the code development industry, the de-facto standard has become a decentralized by design version control system. I am talking, of course, about git. git a priori does not imply the presence of a single “source of truth” - any user, before using the code, needs to clone the repository to their computer and work with their local copy. In addition, the data storage method in git is nothing more than a chain of blocks (fixed facts of code changes - commits), which guarantee the immutability of history. That is, git itself is a kind of blockchain, the consensus between which is achieved manually by the authors themselves through branching and merge requests.
Nevertheless, despite the decentralized nature of git, web2 platforms have taken their place. Now, code development is almost entirely centralized around a relatively small number of platforms like Github, Bitbucket, Gitlab. And this happened precisely because of the introduction of additional tools: DevOps (CI/CD pipelines, built-in functions for detecting vulnerabilities in source code dependencies and much more) and Social Networking (developer reward systems, issue tracking, project management). These tools are not part of the original git protocol and complicate the migration of projects from platform to platform.
The project Radicle was founded specifically with the aim of freeing code developers from the need to depend on large platforms, which we consider as the first component of our Web3-DevOps stack. The project has a quite long history and a number of significant transformations on its way to its current moment. Initially, Radicle was built on top of the then gaining popularity Inter Planetary File System (IPFS), but at some point developers realized that the ways of storing and hashing code repository data in IPFS were incompatible with the ways of storing in git, leading to duplication of information and excessive traffic consumption even in the case of small updates. Gradually, a decision was made to switch to a more minimalist solution - to exchange git patches directly, using the native pack protocol, to make this the main way of data transmission in the “codekeeper” network. This decision served as the beginning of a major refactoring and rewriting of the project from Go to Rust. The new version of the protocol, called Heartwood, draws inspiration from projects such as Secure Scuttlebutt (SSB) and Bitcoin’s Lightning Network.
Later, in 2021, the Decentralized Autonomous Organization (or simply DAO) Radworks was founded on the Ethereum blockchain, the RAD governance token was issued, and the necessary funds were raised for further development of the project. Apparently, the project team does not deny the importance of social and economic components in code development, but at the same time does not try to integrate all supporting tools into their implementation. One such initiative is their project and eponymous smart contract Drips, which is aimed at automatic distribution of donations among open source developers under the slogan “Fund your dependencies”. Within this smart contract, each development project can set up automatic redistribution of received donations for its set of dependencies (packages, libraries).
Just recently, in March 2024, the 1.0.0 release of the Heartwood protocol implementation was released, which means it can already be considered for production scenarios of decentralized development pipelines.
Second Phase - Build, Test, Continuous Integration - Fluence
The next step in our simplified DevOps pipeline is the build stage, which includes more than just code compilation. It involves a range of processes with varying computational resource intensities. However, these computations do not always lead to tangible changes. In other words, not every code change or build initiation results in a release. Often, Continuous Integration (CI) pipelines run on a schedule. The artifacts they produce are typically short-lived and are deleted if not included in a release. Hence, we don’t consider this stage in the development lifecycle as requiring consensus, similar to numerous cloud computing projects that use blockchain for result verification.
The developers of Fluence hold a similar position. This is a project very close to Robonomics, which also intensively uses libP2P as a transport layer and ipfs as a storage layer in its use cases, while focusing on the orchestration of peers and calculations on them without the need for centralized platforms. Let’s take a closer look at them.
Fluence consists of two key components - Aqua and Marine. The former is a domain-specific language (DSL) and is used to manage the sequence of tasks on computing devices, i.e. to orchestrate peers. On the one hand, mastering another language can deter many users, on the other hand, it is an honest step that immediately sets you up for the inevitable future. The fact is that most CI platforms usually offer configuration files in some common formats like YAML or JSON for managing and setting up pipelines. At first, this is really convenient and allows any user without programming skills to start working, but over time, as the needs and, accordingly, the number of configs grow, the lack of so familiar tools for programmers leads to the growth of boilerplate code and the inability to manage complexity. Attempts to make YAML a configuration language using templates also do not solve the problem, which contributes to the emergence of Ad-hoc configuration description languages like HCL (HashiCorp Configuration Language). Aqua offers an immediate solution in the form of an application programming language for the flow of computations, which has a reliable theoretical basis in the form of Pi-calculus, into which Aqua-code is compiled for further execution on peers. This makes the entry threshold into the technology a bit higher, but should ideally provide more stable and maintainable work in the future. Now Aqua is a fairly low-level language, but over time libraries may appear that implement best practices for designing computational flows using convenient mathematical abstractions, which will speed up the development of distributed computations.
Aqua sets the order of computations, but the computations themselves are prepared and carried out using Marine - a component also developed by Fluence. Marine is an SDK (Software Developers Kit) - a set of tools for assembling mutually compatible Webassembly modules, as well as a Runtime - a general-purpose environment for their execution. Modules are relatively independent software components, each of which stores its own state, but can interact with each other through function import/export. A set of interacting modules forms a service, which implements complex behavior and acts as an actor in the Fluence peer network.
Together, Aqua and Marine fully provide what can be called the thinking of a cyber-physical system - that is, all the variety of computations that help make decisions about what actions to take in the outside world to increase the chances of success in the evolutionary race.
Model-based robotics development requires resource-intensive computations. A significant part of the tests of the developed software for robots are carried out in simulators, and reinforcement learning-based algorithms launch such virtual environments hundreds of thousands of times before they achieve the desired agent behavior. Various physics and rendering engines, as well as game engines based on them, can serve as virtual environments. Recently, the Entity Component System design pattern has become widespread in these environments. By the way, the modern version of the well-known in narrow circles robotic simulator Gazebo/ex-Ignition from Open Robotics (they also develop ROS) also uses ECS to increase performance and flexibility. In fact, according to the developers of Fluence, their execution model is well suited for the implementation of distributed architectures built on this principle.
Of course, for compiled and tested software to bring value, it must be deployed on hardware platforms. Hypothetically, it is also possible to deploy software using Fluence. In fact, the developers themselves say that their stack also allows for deployment on peers, and this is indeed the case. However, we believe that consensus is needed and important in the area of interaction with the external environment and physical equipment.
Third Phase - Deployment - Robonomics

An important feature of software is the fact that it does not change the outside world by itself, but serves as a model of the surrounding reality and helps to make some reasoning about it - to build hypotheses, propose a plan of action, launch processes in the outside world using equipment or people. For example, an issue tracker itself is not a system that changes the outside world, it can be called a digital twin of the development team, which in turn brings changes to life. Thanks to the issue tracker, the team can coordinate actions with each other, help each other. In other words, the issue tracker allows maintaining a consensus within the development team - who does what tasks and when - but the change itself is made by people.
When discussing world-changing systems, we refer to physical entities operating in the real world such as smart devices, robots, and autonomous factories. Essentially, Robonomics serves as a bridge from information systems and people to the external world via robotic systems. The importance of safety cannot be overstated, as neglecting it could lead not only to capital losses, but also real disasters.
Despite the critical nature of these systems, the first secure decentralized storage systems appeared not in the industrial sector, but in the financial sector. Bank accounts proved to be a more enticing target for computer criminals than household appliances, most of which lacked network connectivity. The technology used to secure banking information systems has evolved significantly, from SWIFT to Ethereum, and is now gradually being implemented in other economic sectors.
Robonomics is at the forefront of these secure, decentralized networks, taking charge of the final phase of the Web3 DevOps conveyor - deployment.
In general terms, a deploy is putting a system into operation. A more familiar synonym for this term is installation (install) - an event after which the produced and delivered system (an instance of a certain type of equipment, an executable file of software) begins its functioning inside a higher-level system. What is good about blockchain in this case? First of all, when releasing any version of the program to the outside world, it is always important for us to understand what exactly was released. During development, versions can change very often and this is normal, so it is not advisable to put all information about them in the blockchain. However, the event of release or launch requires fixation, so that when receiving feedback we can clearly understand with which exact version of source codes or drawings we need to compare this feedback. The blockchain can serve as a reliable repository of information on all software updates of devices connected to it.
Moreover, the installation process must be consistent, as discrepancies can lead to configuration collisions. These collisions can arise from mismatching software module versions, deploying different systems within the same space, and other related issues. For instance, the previously mentioned car collision at an unregulated intersection is an example of such a collision. In the context of software deployment, collisions may manifest as API violations, insufficient hardware capabilities, or writing to prohibited or unsafe memory locations. Robonomics can store the configurations of connected equipment and, at the consensus algorithm level, prevent such states.
You can use a special launch call to deploy software in the Robonomics parachain, which allows you to start a node connected to the blockchain with additional parameters. The parameter can be a unique identifier in the IPFS content distribution network, from which you can get a software image, a binary file, source code for the operating system configuration, or even a bash script! Since each transaction in the network is signed with a cryptographic key, in essence such a call in the parachain is equivalent to a public release signature.
For more complex scenarios, you can use a digital twin, which allows to set a correspondence table between arbitrary data 256 bits long and an account in the Robonomics network. Thus, you can keep a log of configuration version changes for device accounts in the Robonomics network. In traditional configuration and deployment systems, hosts are usually specified as nodes - these are computers with a DNS name or IP address. In the case of Web3, hosts are identified thanks to their public cryptographic keys, to which accounts are attached. To change the configuration, you can add a new content identifier, from which the device will receive a new version of the software and update.
Putting it all together
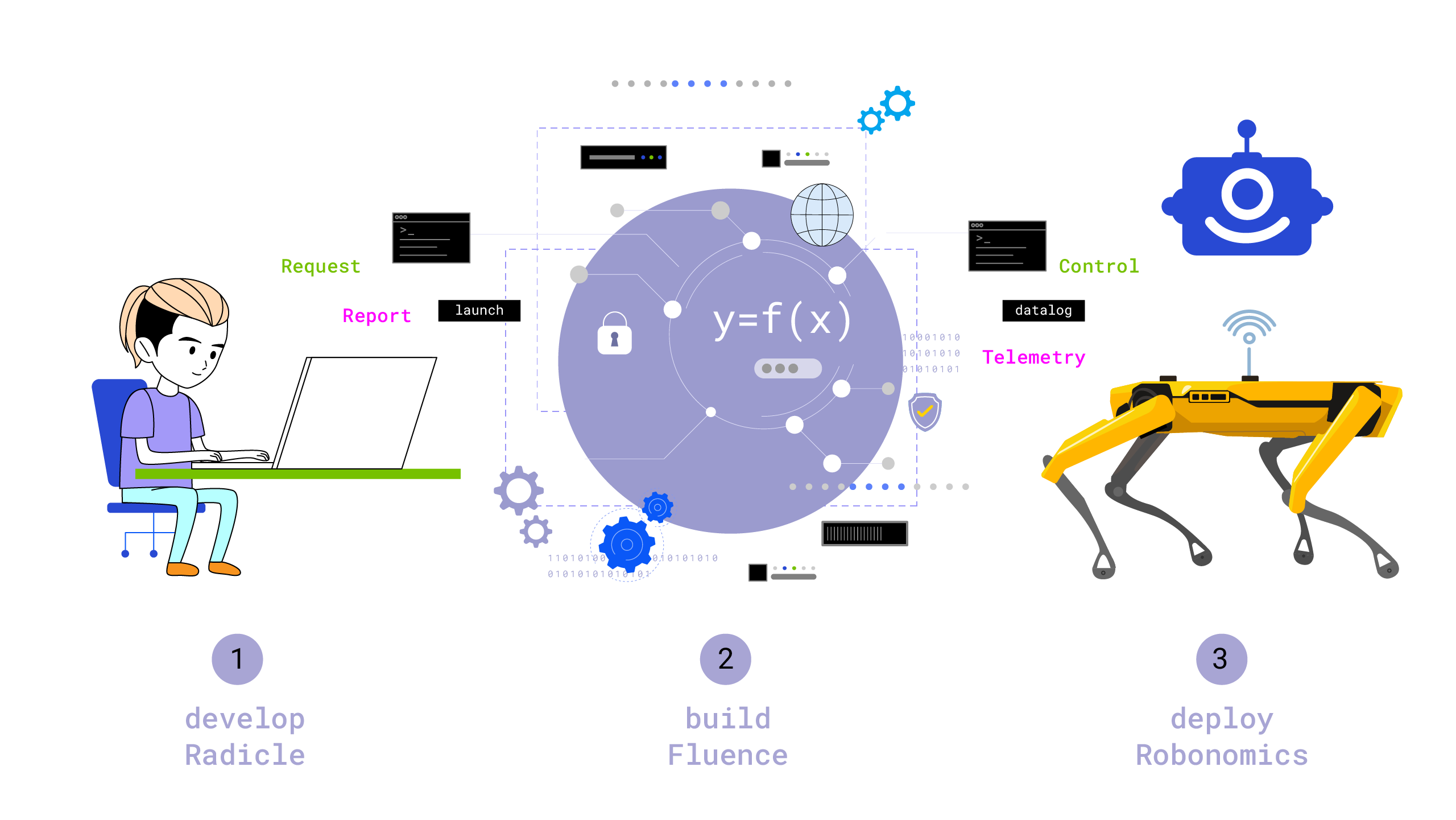
So, let’s try to look at this from a bird’s eye view. People make up the core of our large cyber-physical system. People are chaotic, unpredictable… and that’s good! They generate new meanings, ideas, products. They actualize their will to change the world. Now, in the 21st century, it is not necessary to change the world with your own hands. There are tasks in front of humanity for which human hands are not the most suitable tool. Instead, there are machines, which now serve as the conductor of our will. Machines, on the contrary, are strictly deterministic and predictable. And people love this, yes. They love it when the train arrives at the station on time, and the quality of the products they consume is always predictably excellent. For this, people use networks. Lots of networks! They generate ideas on the Radicle network, machines gather and test them into executable modules on the Fluence network, and then deploy them on robots on the Robonomics network. The robots, in turn, transform the environment, and their sensors, also through Robonomics, provide feedback to people to make a decision - the cycle is closed. This is a cycle of continuous improvements, where everyone has their place. There is no contradiction between the machine and the human - both of them in harmony create a new order of humanity - interplanetary humanity.