Introduction to Digital Twins
Digital twins are not a new concept; they emerged in the early 1990s and have since periodically captured the attention of researchers, engineers, and founders. Now, in 2024, digital twins are again in the spotlight—since 2016, according to Google Trends, interest in them has steadily grown. We believe it's important to familiarize readers with this concept, as the term is often interpreted loosely, making it challenging to understand. Igor Brylev [movefasta]
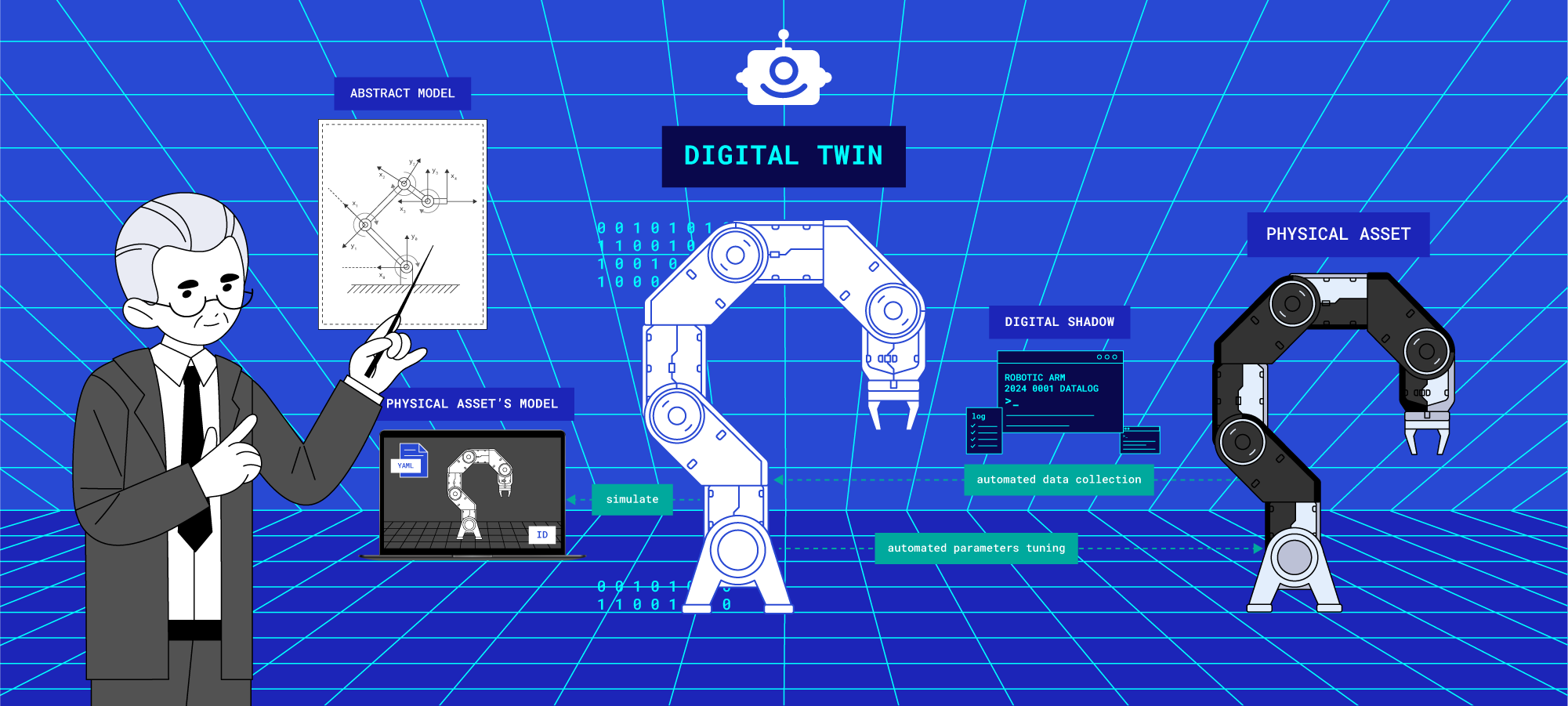
When people first hear about digital twins, they often think of computer models. Even experienced robotics engineers sometimes make this mistake. It’s understandable because for a long time, computer modeling has been used to design things like cars or factories before they’re actually built. Think about a 3D model you might see on a computer screen. You can look at its shape, figure out how big it is and how much it weighs, check how strong it is, and even run tests on it. But here’s the thing: this isn’t really a digital twin. So what makes a digital twin different?
Models and Their Types
A traditional engineering model is basically just a blueprint. It doesn’t describe one specific object, but rather a whole group of similar objects. (When we say “object,” we mean anything that exists in the real world and takes up a particular space.)
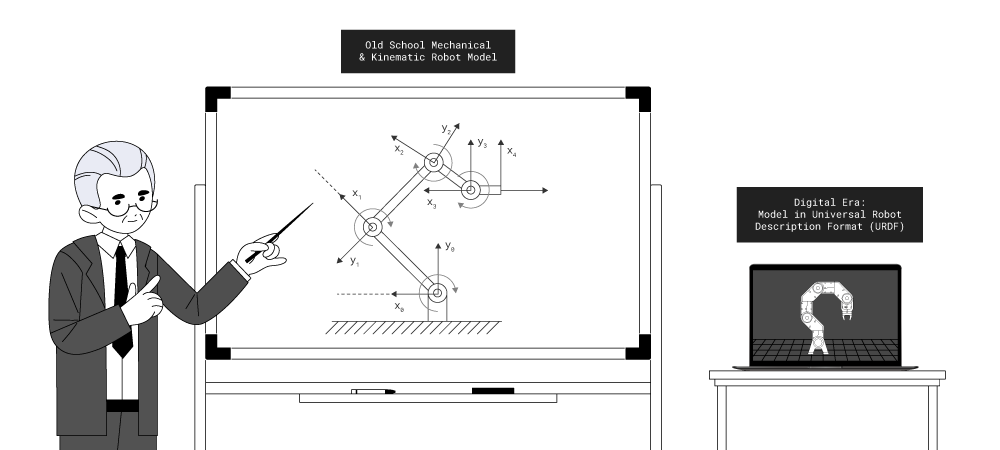
A model is a description of some class of objects. It can be digital, but not necessarily. A model is primarily a description of an abstract, rather than a specific/physical object.
When a system is built using a blueprint or engineering plans, it doesn’t stay exactly the same forever. As it’s used, it starts to change bit by bit. Over time, it can become very different from how it was when it was first made. This is why it’s important to keep updating our model or description of the system. We need to make sure our model matches what the system is really like now, not just how it was at the beginning. This helps us when we want to think about the system or use computers to work with it. By keeping our model up-to-date, we can make sure we’re dealing with the system as it really is, not how it used to be.
This is how we come to the need to distinguish between general models (or class models) and digital models (or instance models). A general model describes a class of objects and its main properties, while a digital model adds to this description data that allows us to judge a specific representative of this class - its unique name, identifier or serial number, position in space and time, calibration coefficients, and other data that allow linking this description to a real-world object. This is why a virtual world cannot be a digital model if it is not associated with a specific physical asset, and actions in this virtual world do not lead to changes in its parameters in real life.
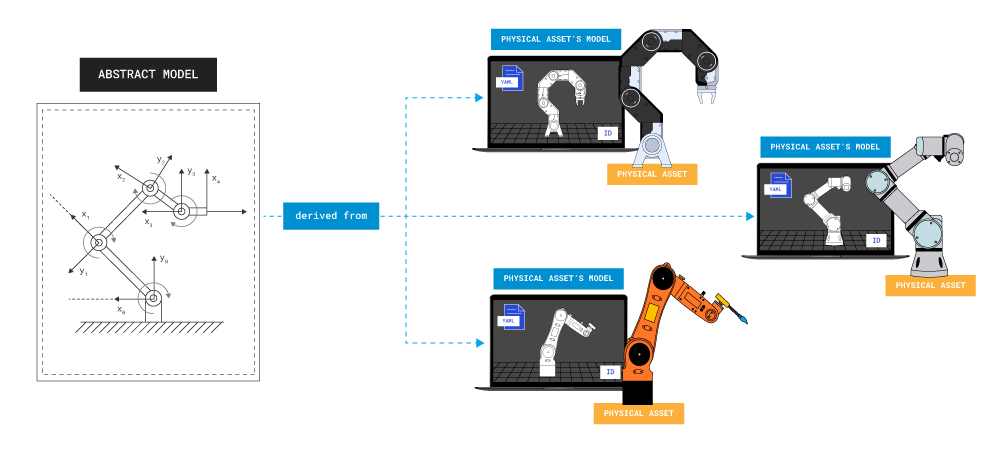
Multiple physical objects can correspond to a single abstract object.
We started this article with examples from technology and manufacturing. But now we’re using broader terms like “systems” and “objects.” This is because digital models can be used for more than just machines. In fact, anything in the real world can have a digital model. This could be something as small as a living cell or as big as an entire ecosystem or even a star system.
Let’s provide examples of digital models from other domains:
| Physical Object | Class Model | Digital Model |
|---|---|---|
| Citizen | Standard passport format | John Doe’s passport |
| Patient | Medical reference guide describing disease symptoms | Maurice Bruchier’s medical record |
| Automobile | BMW X5 User Manual | Maintenance records for BMW X5 (serial number: 29591376838) |
These examples are intentionally simple to be familiar to every reader. Note that all these examples mention models used long before the digital age! This illustrates a key feature distinguishing a digital model from a conventional one—the recorded history of its state changes over time, preserved on some information carrier. This carrier could be anything; data might even be manually collected and written in ink on paper. So why weren’t these called digital twins (or models) before? The primary reason is automation—both in data collection and in the computations performed on this data.
Digital: From Shadow to Twin
Until recently, humanity was quite limited in its ability to work with information - to store it, copy it, keep it up to date, and perform computations on this information. Books and scribes were expensive, and libraries regularly burned down. In such circumstances, it was not possible to keep records of all objects in the surrounding world on paper. The computer era brought about radical quantitative changes in this area. Literally everything increased: the volumes of stored information, the speed of its collection, and the ability to quickly process and transmit it over communication networks to any distance. All of this together provided unprecedented ease in creating digital models for literally anything, and most importantly - human involvement was no longer required for obtaining and processing information.
Previously, information about the operation of devices was entered by people (for example, into some kind of graph or table).
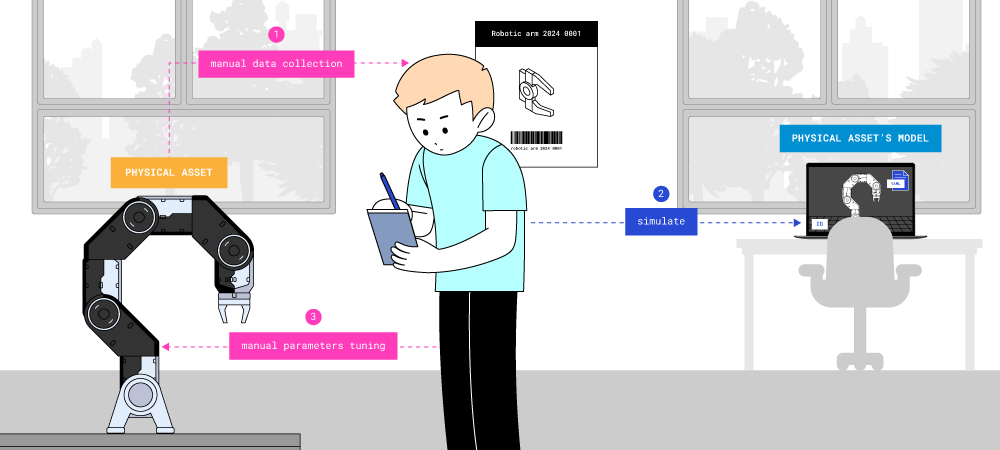
A model of a physical object is a description of a specific instance, manually compiled and incorporating its operational history (log or datalog of historical data).
Of course, this was time-consuming, expensive, and led to errors in information transmission. The addition of microchips to devices and the development of the information technology industry made it possible to continuously collect information without human operators. While devices used to be released and then lived their independent lives (including modifications), now each smart device can provide feedback about its state and record historical data. The digital model can receive up-to-date data about the system’s state automatically. In this case, the digital model becomes a digital shadow - a log of changes in the system’s states during its operation, collected autonomously.
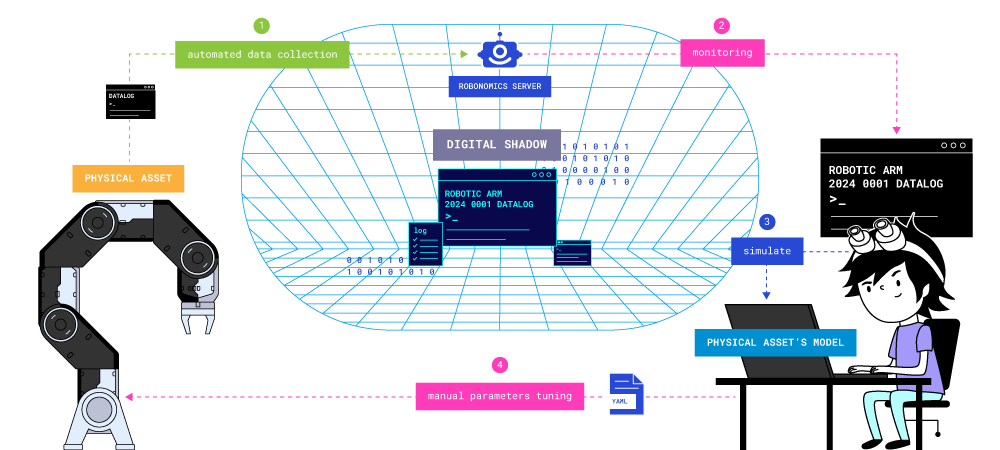
A digital shadow is an automatically compiled record of an object instance, including its historical data.
In the case of living people, digital shadows are user profiles on various digital platforms - online stores, social networks; for organizations, it can be the history of bank account transactions; for computers - various program operation logs. In Robonomics, a digital shadow is created by calling datalog, which adds another entry to the history of changes of the physical parameter we need.
But where did the concept of a digital shadow come from? Why wasn’t this automatically collected log of system changes called a digital twin? To understand this, we need to ask ourselves why people keep records of historical data in the first place. The answer is simple - accounting allows us to understand how to influence a physical object to obtain the desired behavior. To implement a full control cycle, we need not only to be able to automatically collect data but also to automatically make decisions about changing operating parameters. Significant progress has also been made in this direction - humanity has learned to automate the calculation process, which allows predicting model behavior with changing input parameters. With classical models, calculations were performed manually - it was necessary to formulate the task, describe its conditions, and solve it by applying the laws of natural science and their corresponding mathematical equations. The automation of calculations provided the ability to simulate the model’s operation, that is, to make it interactive.
Actually, a digital twin is precisely such an entity that automatically receives data (collecting a digital shadow), performs calculations on them (making decisions about changing the state), and then carries out some actions on the system.
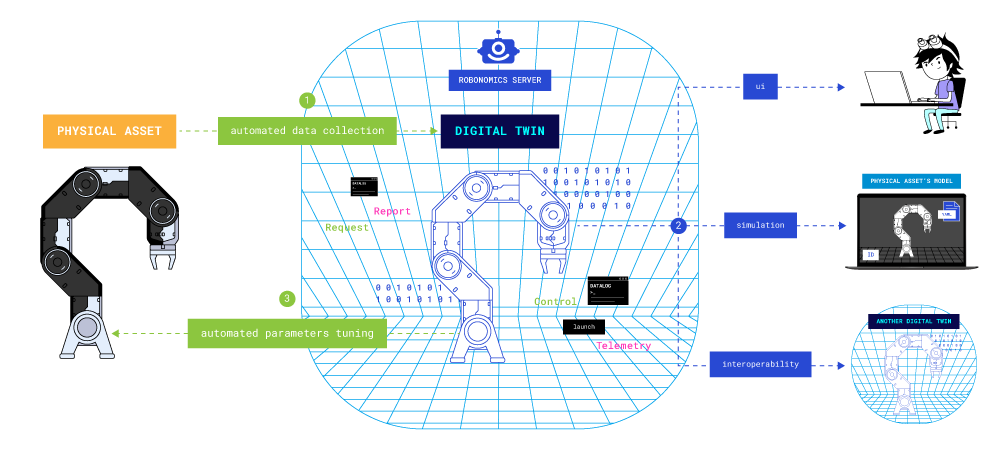
A digital twin is an interactive model connected to a physical object that can automatically make decisions to change its operational parameters.
In other words, it’s a working computer program or simulation model directly linked to the control object. If the simulation model is not yet tied to the control object and lacks a unique ID, serial number, and operational history, it is called a digital twin prototype.
Digital twins are directly related to the so-called 4D extensionalism - an approach to modeling the world where objects are not three-dimensional, but four-dimensional - the dimension of time is added to them. Such models reflect not only the geometric parameters at the time when the system was released but also its entire history throughout its operation, as well as its possible future(!) states. Moreover, data collection is carried out not only during a short period, as in classical control systems, but throughout the entire life of the system. Systems that allow linking different states of a digital twin over time are called a digital thread.
So, after a rather lengthy prelude, we can summarize all of the above in a relatively concise definition:
A digital twin (DT) is a digital representation of a physical entity or process modeled with the purpose to improve the decision-making process in a safe and cost-efficient environment where different alternatives can be evaluated before implementing them.
Basic classification
Digital twins are mainly distinguished by the time range in which they operate and how much data they can consider in the decision-making process about changing the operational parameters of their physical world counterparts. The terminology and classification, as in any developing field, are still being formed, and there is no single established meta-model for naming different types of twins. Nevertheless, we can already identify the following main categories.
Reactive twins
They perform operational control, continuously receiving data from sensors and changing current parameters in real-time. This type of twin includes Model-Based control, where a simplified model of the controlled object is embedded in the control program - for example, an onboard computer (embedded system) working inside the object of its direct control, which is very limited in computational resources, so the model of the object embedded in it must also be quite simple, but sufficient for effective operation. However, unlike a classic control program, a digital twin can exist “separately” - for example, in a virtual machine on a remote computer or in the cloud, so the simulation model embedded in it can be more detailed and therefore more accurate.
This variant of digital twins can also be called cybernetic. Cybernetics as a science describes control processes in nature and technology, and since any control implies a controller and a controlled entity, the digital twin is essentially such a cybernetic control agent.
A reactive twin operates at a fairly low level. Its program must be able to interpret system service information - for example, temperature sensor readings of the onboard controller for internal use, to prevent overheating or other undesirable situations. The feedback method for influencing the physical twin is “fine” tuning of parameters without changes to software versions or physical construction.
Digital siblings
In literature, this type of digital twin is often referred to as “what if” twins. These twins allow simulating some hypothetical situations that may occur in the future and take measures to prevent negative scenarios or improve efficiency. Unlike the reactive twins discussed above, which have a direct connection to the control object and are presented in a single instance, situational twins can be copied and deployed in any number of instances on any number of computers. The “detachment” from the control object lies in the fact that the simulation model is placed in a virtual environment where information comes not from real sensors, as in the case of reactive twins, but from a virtual reality created by us to reproduce a hypothetical situation, and the control action is carried out with the simulation model itself, not with actuators like motors or heating elements. These twins utilize external or cloud computing power, and therefore can take into account a much larger number of parameters than reactive ones.
Also, in this case, it is possible to change the course of time in the simulation model. Reactive twins must be able to respond in time to changes in the state of the physical twin, so they are forced to make decisions exclusively in real-time conditions. Situational twins are free from this limitation and can use, in addition to real time, simulation time, which can be both slower and faster than real time. Time slowdown is inevitable in cases where it is necessary to take into account a large number of parameters and, accordingly, perform a large number of calculations to use highly detailed simulation environments containing very accurate physics engines and environment rendering. Time acceleration helps in cases where it is necessary to produce a large number of simulation runs - for example, to form a dataset or for reinforcement learning.
The feedback method with the physical twin here is software updates - both system and decision support. For example, during multiple launches of the digital sibling, a program being developed for a robot to assemble a new product is tested, after which this software is loaded into the digital twin - the robot and production receive a new capability.
Industry’s State of the Art
Now that we have defined the concept of a digital twin and its main types, we can ask ourselves how these twins should be designed, implemented, and used in practice. Since a digital twin is a reflection of a physically existing system, the ways to describe them depend on how we understand this world as a whole. This is why the digital twin movement grew out of modeling, simulation, and predictive analytics systems, which reflects the actual state of affairs, because in reality all these systems are usually subsystems of a digital twin. In this regard, we can distinguish between the domain-specific and informational components of twin description methods.
The domain-specific component is related to different ways of representing knowledge about the system - for example, even a geometric model can have several variants - a CAD model to reflect the system structure, a dimensional model for movement simulations in physics engines, a simplified model with PBR textures for game engines, a model for highly realistic rendering. Additionally, models can be nested within each other - for instance, a car’s gearbox and the car itself are often developed by different companies, but during simulation, the car model should include the gearbox model and interact with it in some way. In this regard, we can highlight the open source Modelica Consortium, which develops open standards to exchange dynamic simulation models such a Functional-Mockup-Interface, methods of composition (see System Structure and Parameterization) for multi-domain modeling and distributed simulation (see Distributed Co-Simulation Protocol).
The other component is informational. It is higher-level and describes software interfaces or APIs for accessing information about the digital twin. Currently, there are many diverse standards, among which there is no clear leader. Now we can highlight the following key trendsetters in this direction:
- Asset Administration Shell (AAS) by Industrial Digital Twin Association
- Digital Twin Definition Language (DTDL) by Microsoft Azure
- NGSI-LD by European Telecommunications Standards Institute
- Web of Things by The World Wide Web Consortium (W3C)
Many of the mentioned standards are based on or strive for integration with a technology stack called the Semantic Web. This technology stack was proposed in the early 2000s by the founders of the internet as a response to the challenges faced by the first version of the web, which it did not adequately address. It turned out that it was not enough to simply physically connect computers to each other and ensure the transfer of information between them. For full-fledged interaction with each other, systems must “understand” each other, that is, have certain agreements on how they describe reality, which goes beyond the classical OSI network interaction model (on which the modern internet is built) and adds new levels to them. Subsequently, based on the set of Semantic Web standards, semantic interoperability standards also emerged, prescribing methods for aligning information systems with each other. These include, for example, ISO 15926, known in system’s engineering communities, developed to describe the lifecycle of complex systems, but which has not gained widespread adoption.
The internet has fragmented into large platforms or ecosystems, each reluctant to achieve “mutual understanding” with others. As a result, key industry players are hesitant to support semantic integration standards. This administrative, rather than technical, barrier prevents effective interaction between systems. Digital twins may face similar challenges, potentially unable to “understand” each other due to differing standards. Web3, with its emphasis on legal aspects (the administrative component), might reignite interest in this topic, potentially leading to a new evolutionary stage.
Linking Digital and Physical Assets
Blockchain networks, as a significant part of Web3, were initially formed around the financial sector, and their physical embodiment to this day are database state holders and validators. Both types of devices are nothing more than computational nodes that do not directly change the state of the physical environment - they have no sensors or motors. Unable to directly change their “habitat” environment, blockchain networks become focused on developing themselves and turn into a slightly more advanced, but still financial bubble, which raises doubts among the general public and hinders mass adoption of the crypto industry. Nevertheless, the resources that this industry has absorbed at the moment can manifest themselves constructively - in the ability to change the world and solve those problems that the modern global economic system cannot solve to this day. Including with the help of digital twins.
When we talk about the ability to change the world in the 21st century, we primarily mean robot agents, so the topic of digital twins and their reflection in information systems is extremely important for linking the world of relationships of private cryptographic key owners (which is formally what blockchain is) with technical systems that are developed and built by people. Blockchain in this respect is quite simple - it usually abstracts from the semantics of the information stored in it - it does not endow transactions and accounts with any semantic content. Users fill it with semantic content by creating named assets (tokens) that reflect some idea. To this day, tokens predominantly reflect the community’s faith in a particular company (in the case of Governance) or some expected utility (in the case of Utility). Moreover, Utility tokens are usually concentrated on IT services, that is, entities comparable to the blockchain level. And few try to make a token that could reflect the physical state of some real system. The physical state of the world is de facto assessed by market participants, often relying on unreliable and often contradictory information. Oracles can only partially solve this problem, as they can also be subject to distortions. This is where the growth potential of Web3 and the mission of Robonomics lie - in ensuring that the physical world is directly connected to markets, and not through intermediaries in the form of mass media or asset holders.
In relation to real-world objects, blockchain assets can play different roles. Fungible tokens can be similar to macro-characteristics - they reflect the state of a large number of agents. Just as the temperature of a gas reflects some average indicator of the entire set of kinetic energy values of gas molecules, the token rate reflects the degree of society’s interest in a particular project or development team. Non-fungible tokens have a somewhat different nature - this is a record in a decentralized registry reflecting some unique object that cannot be divided without destroying it. It is this property that makes NFTs suitable for real-world objects or digital twins. An NFT can act as a unique identifier for a system instance, containing a digital passport, a link to its simulation model for running simulations, and a datalog of its changes in the past.
Web3 as Internet of Digital Twins
Just as the historical internet came to the idea of the necessity of a semantic network, Web3 will also have to take this step, but bring it to its logical conclusion. And there are already certain progressive steps here.
In particular, alternatives to DNS have emerged in the form of Namecoin and ENS, and immutable content-addressable resource identifiers (in the form of IPFS hashes) have begun to be used as links, guaranteeing the immutability of content. If we look at the fundamental standards underlying the internet, we can notice how, for example, in the list of universal resource identifier (URI) schemes, in addition to traditional http, https, ftp, mailto, new ones have appeared - such as ipfs, ipns, Web3, bitcoin, ethereum. Yes, Web3 still uses the IP network protocol to connect computers to each other, but it already allows for significant abstraction from it, transferring identification to the level of cryptographic verification. The network has ceased to connect impersonal computers with IP addresses, and has begun to connect people as owners of cryptographic keys. You can be located anywhere, but having a private key allows you to be connected with other similar users regardless of their location, including transferring value to each other. This is particularly relevant for mobile robotics, where location can be highly variable and dynamic.
The aforementioned semantic web stack, as well as the possible reason for its failures, was largely built on the original foundation of the “old” internet. For example, on DNS, which is actively used to identify URI resources. DNS is a global, administratively managed routing table through which users could access network resources via human-readable addresses. This feature cannot provide the necessary degree of reliability when describing models of real-world objects for the interaction of automatic systems. For instance, when referring to any model (or prototype) of a digital twin in the form of a resource with a URI in the form of a domain, we can never be sure that the content of this model will not change to something radically opposite. This may be a potential growth point for Web3 as a kind of interface to unmanned robotic systems through their digital twins. For example, we can describe a model of any system in the form of multi-nested IPLD structures (each level of which can describe a special semantic layer in the system model), record their addresses in the blockchain, and be confident that systems and devices relying on these models will never be “deceived” regarding their content. This can become a reliable basis for communication of autonomous automated systems in the future.